



How to name variables in a clinical research database
A good variable name is rather to be chosen than riches


(Spanish version below)
Over the past 2 decades, I have made many databases to conduct clinical research studies. I used to do them in Access or Excel and then import them into SPSS. Nowadays I frequently use the REDCap online electronic case report form, which I love.
There is one detail we are going to talk about today: in your database, you have to choose a name for each variable. A unique name that identifies it in the database, then exports well to the statistical analysis program and is easy to search for ourselves or others.
I have had the same problems over and over again with variable names:
- When I analyze databases with many variables I find it difficult to find specific variables because their names are not logical or consistent with respect to other variables.
- When I have shared databases with other researchers, I have had to write an explanatory document of the database, explaining what each variable means and how it is coded. It has meant extra work for me on a base that I had designed sometimes years before!
- I have had problems when exporting or analyzing variables with names that are too long, especially when doing operations with variables that result in the automatic creation of new variables, since the name is automatically lengthened and can give errors due to excess length.
#WATERFALLtrial was an open-label international randomized clinical trial with data from 249 patients. The database had 537 variables.
537 variables are a lot.
I confess that my ability to memorize data is very limited, well below the population average. I must resort to logic to compensate. Many times, you change the order of variables in the database when analyzing it, and if the names do not follow logic, you waste time finding them.
When analyzing a complex and variable-rich study like #WATERFALLtrial it is difficult to find a specific variable. SPSS allows you to search by variable name and allows you to sort them alphabetically. Even so, I always had trouble finding them in studies with many variables. My failure was always the same: I impulsively decided on each variable's name while designing the study. But not anymore, now I have a method, let me share it with you.
When you design the database of a study, start well from the beginning, this is very important to facilitate the later publication of the protocol, the statistical analysis, the sharing with other researchers, and the final publication of the study. The steps to follow for excellent management of the choice of the name of the variables are the following:
1. WRITE A TABLE OF YOUR VARIABLES. When writing the protocol it is very useful to make a table with your variables that includes the name you give them in your database, their definition and characteristics. This has great advantages 1) it allows you to organize the variables in a more logical way and helps you to decide what to name them, it is much better than inventing names directly in the software, it helps you to have more coherent names; 2) you will have an explanatory document of your database that will be very useful if you share it with other people like the statistical analyst or other colleagues who want to use the data; 3) you will have a table that you can add to the protocol of your study and then publish as complementary material in the final article of your study, which increases the solidity of the publication.
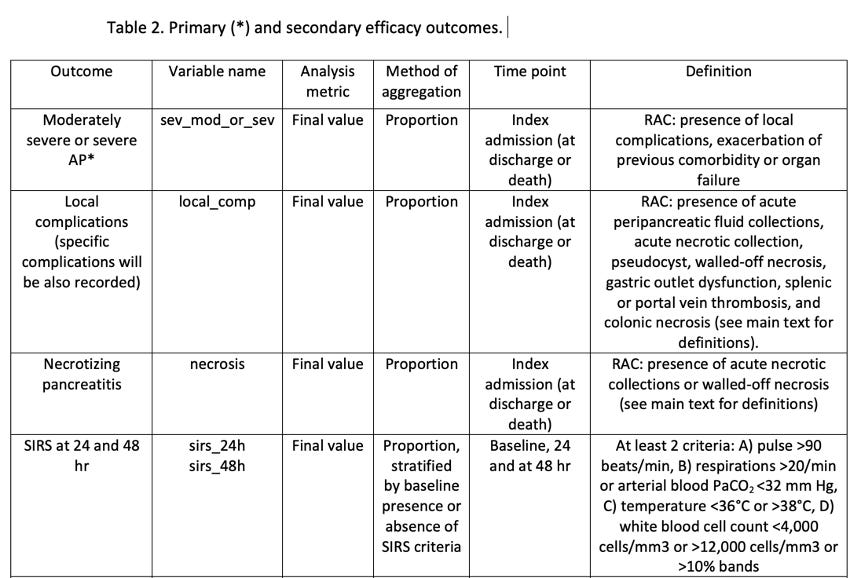
Real sample table of variables, protocol for my new clinical trial, #WATERLANDtrial
2. LENGHT BALANCE. Maintain a good balance between the length of the name of the variable and the concept it represents. Sometimes it is easy (e.g., "age"), but sometimes it is more complex, e.g., "acute peripancreatic fluid collection". The abbreviation apfc will be difficult for someone who does not frequently deal with acute pancreatitis, such as your statistical analysis expert. Do not use non-standard, non-easily identifiable abbreviations. When naming your variable, think of 2 things: A) how you would look up the variable if you don't remember the name, and B) whether the name will make sense to other people using the database. In many programs, for example, REDCap or SPSS, you can duplicate variables or integer forms so that the name of the new variables changes by adding an ending of your choice. For example, of_transient becomes of_transient_24h in a new form. When choosing the length of a variable, keep in mind that automatic modifications of that variable in the database and statistical programs will have a longer name unless you change them manually one by one, so do not use very long words, even if they are within the limits allowed by the program, you can exceed the number of characters allowed by the program and get errors.
3. RESTRICT SYMBOLS. I only use letters, underscores, and numbers, e.g. sirs_24h. There may be problems when switching from one program to another. For example, you may use SPSS, but sometimes a collaborator may need another program such as SAS, with other rules. Do not use a hyphen or underscore at the end of the variable, e.g. sirs_, only use them to separate letters within the variable name and make it easier to understand. Better use underscore than hyphen for this, it gives fewer problems in analysis programs.
4. NUMBERS: AT THE END. Do not use numbers at the beginning of the name, e.g. 24h_sirs, it does not contribute anything to the search and may produce problems in some programs. First you search for the term "sirs" and then you get all the different times: sirs_baseline sirs_24h sirs_48h sirs_72h. If you start with 24h and do a search with that term, you can find dozens of variables measured at that time: 24h_creatinine 24h_bun 24h_glucose 24h_sirs… It has happened to me many times, I really hate that error, I HATE IT :c
5. MAKE GROUPS. Include logical subclassifications on the variables to help you find them. I use a system that has between 2 and 3 levels of information: general group, specific concept, and time in which it was measured, if applicable. Example: in acute pancreatitis there are several types of organ failure. First, there is organ failure according to its duration: transient if it lasts up to 48 hours and persistent if it lasts more than 48 hours. Then whether it is a single-organ or multi-organ failure. The patients may have respiratory, renal, or cardiovascular failure. Finally, in a study, we may want to record whether there is organ failure at a specific time, for example, on the first, second, and third days. As they are all types of organ failure and we will probably analyze them all at the same time, it is very useful to categorize them first with some letters that group them together, for example: of_
Then we put the specific concept:
of_transient
of_persist
of_single
of_multiple
of_resp
of_kidney
of_shock
If you want to put the time that has been measured, you add it at the end:
of_shock_24h
If you call your variables: transient_of persist_of or 24h_shock then it will be difficult to find them for the analysis of the different types of organic failure and you will lose time.
6. AVOID FORBIDDEN WORDS. Each program has words that cannot be used in the name of the variables because they are commands used by the program, for example, in SPSS you cannot use ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO or WITH. It is good advice to avoid what is forbidden, my dear Clinical Research Lovers, although there may be some exceptions to this general rule.
The true secret of happiness lies in taking a genuine interest in all the details of daily life (William Morris)
******************
Versión en español:
Durante las dos últimas décadas, he creado muchas bases de datos para realizar estudios de investigación clínica. Antes las hacía en Access o Excel y luego las importaba a SPSS. Hoy en día utilizo con frecuencia la herramienta online para formularios electrónicos online REDCap, que me encanta.
Hay un detalle del que vamos a hablar hoy: en tu base de datos tienes que elegir un nombre para cada variable. Un nombre único que la identifique, luego se exporte bien al programa de análisis estadístico y sea fácil de buscar por nosotros mismos o por otros.
He tenido los mismos problemas una y otra vez con los nombres de las variables:
- Cuando analizo bases de datos con muchas variables me resulta difícil encontrar variables concretas porque sus nombres no son lógicos o coherentes con respecto a otras variables.
- Cuando he compartido bases de datos con otros investigadores, he tenido que escribir un documento explicativo de la base de datos a posteriori, explicando qué significa cada variable y cómo está codificada. ¡Me ha supuesto un trabajo extra de una base que había diseñado a veces años antes!
- He tenido problemas al exportar o analizar variables con nombres demasiado largos, especialmente al hacer operaciones con variables que dan lugar a la creación automática de nuevas variables, ya que el nombre se alarga automáticamente y puede dar errores por exceso de longitud.
El #WATERFALLtrial fue un ensayo clínico aleatorizado internacional abierto con datos de 249 pacientes. La base de datos tenía 537 variables.
537 variables son muchas.
Confieso que mi capacidad para memorizar datos es muy limitada, muy por debajo de la media de la población. Debo recurrir a la lógica para compensar. Muchas veces, cambias el orden de las variables en la base de datos al analizarla, y si los nombres no siguen la lógica, pierdes tiempo encontrándolos.
Cuando se analiza un estudio complejo y rico en variables como #WATERFALLtrial es difícil encontrar una variable específica. SPSS permite buscar por nombre de variable y permite ordenarlas alfabéticamente. Aun así, siempre tuve problemas para encontrarlas en estudios con muchas variables. Mi fallo era siempre el mismo: decidía impulsivamente el nombre de cada variable mientras diseñaba el estudio. Pero ya no, ahora tengo un método, permitidme compartirlo con vosotros.
Cuando diseñes la base de datos de un estudio, debes empezar bien desde el principio, esto es muy importante para facilitar la posterior publicación del protocolo, el análisis estadístico, la puesta en común con otros investigadores, y la publicación final del estudio. Los pasos a seguir para un excelente manejo de la elección del nombre de las variables son los siguientes:
1. ESCRIBE UNA TABLA CON LAS VARIABLES. Al redactar el protocolo es muy útil hacer una tabla con tus variables que incluya el nombre que les das en tu base de datos, su definición y características. Esto tiene grandes ventajas: 1) te permite organizar las variables de una forma más lógica y te ayuda a decidir qué nombre ponerles, es mucho mejor que inventar nombres directamente en el software, te ayuda a tener nombres más coherentes; 2) tienes un documento explicativo de tu base de datos que te será muy útil si lo compartes con otras personas como el analista estadístico u otros compañeros que quieran utilizar los datos; 3) tienes una tabla que puedes añadir al protocolo de tu estudio y luego publicar como material complementario en el artículo final de tu estudio, lo que aumenta la solidez de la publicación.
Ejemplo real de tabla de variables, protocolo para mi nuevo ensayo clínico, #WATERLANDtrial
2. EQUILIBRIO DE LONGITUD. Mantén un buen equilibrio entre la longitud del nombre de la variable y el concepto que representa. A veces es fácil (por ejemplo, "edad"), pero a veces es más complejo, por ejemplo, "colección aguda de líquido peripancreático". La abreviatura calp resultará difícil para alguien que no trate frecuentemente con pancreatitis aguda, como tu experto en análisis estadístico. No utilices abreviaturas no estándar, no fácilmente identificables. Al nombrar tus variables, piense en 2 cosas: A) cómo buscarás la variable si no recuerdas el nombre, y B) si el nombre tendrá sentido para otras personas que utilicen la base de datos. En muchos programas, por ejemplo, REDCap, puedes duplicar variables o el programa puede crear nuevas variables basadas en variables ya existentes; estas nuevas variables tienen un nombre nuevo automático añadiendo una terminación de tu elección. Por ejemplo, of_transient se convierte en of_transient_24h en un nuevo formulario. Cuando elijas la longitud de una variable, ten en cuenta que las modificaciones automáticas de esa variable en la base de datos y en los programas estadísticos tendrán un nombre más largo a no ser que las cambies manualmente una a una, por lo que no utilices palabras muy largas, aunque estén dentro de los límites permitidos por el programa, puede dar lugar a errores.
3. RESTRINGE LOS SÍMBOLOS. Yo sólo utilizo letras, guiones bajos y números, por ejemplo sirs_24h. Puede haber problemas al cambiar de un programa a otro. Por ejemplo, puede que uses SPSS, pero a veces un colaborador puede necesitar otro programa como SAS, con otras reglas. No utilices guiones ni guiones bajos al final de la variable, por ejemplo, sirs_, utilízalos sólo para separar letras dentro del nombre de la variable y facilitar su comprensión. Mejor usar guión bajo_ que guion estándar- para esto, da menos problemas en los programas de análisis.
4. NÚMEROS: AL FINAL. No utilices números al principio del nombre, por ejemplo 24h_sirs, no aporta nada a la búsqueda y puede producir problemas en algunos programas. Primero buscas el concepto “sirs”, luego obtienes todos los diferentes tiempos. Si empiezas por 24h y haces una búsqueda con ese término, encontrarás a lo mejor decenas de variables medidas en ese momento: 24h_creatinine 24h_bun 24h_glucose 24h_sirs… Me ha pasado muchas veces, realmente odio ese error, LO ODIO :c
5. HAZ GRUPOS. Incluye subclasificaciones lógicas en las variables que te ayuden a encontrarlas. Yo uso un sistema que tiene entre 2 y 3 niveles de información: grupo general, concepto específico y momento en que se midió, si procede. Ejemplo: en la pancreatitis aguda hay varios tipos de fallo orgánico. En primer lugar, hay fallo orgánico según su duración: transitorio si dura hasta 48 horas y persistente si dura más de 48 horas. A continuación, si se trata de un fallo de un solo órgano o multiorgánico. Los pacientes pueden tener fallo respiratorio, renal o cardiovascular. Por último, en un estudio podemos querer registrar si hay fallo orgánico en un momento determinado, por ejemplo, en el primer, segundo y tercer día. Como todos son tipos de fallo orgánico y probablemente los analicemos todos a la vez, es muy útil categorizarlos primero con unas letras que los agrupen, por ejemplo: of_ (de organ failure en inglés)
Luego ponemos el concepto específico:
of_transient
of_persist
of_single
of_multiple
of_resp
of_kidney
of_shock
Si quieres poner el tiempo que se ha medido, lo añades al final:
of_shock_24h
Si llamas a tus variables: transient_of persist_of o 24h_shock entonces será difícil encontrarlas para el análisis de los diferentes tipos de fallo orgánico y perderás tiempo.
6. EVITA LAS PALABRAS PROHIBIDAS. Cada programa tiene palabras que no se pueden utilizar en el nombre de las variables porque son comandos utilizados por el programa, por ejemplo, en SPSS no se puede utilizar ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO o WITH. Es un buen consejo evitar lo prohibido, amantes de la investigación clínica, aunque puede haber excepciones a esta regla general…
El verdadero secreto de la felicidad es interesarse por todos los detalles de la vida cotidiana (William Morris)